
Pandasでは、describe()というメソッドを使うことで、データの基本的な情報を確認することができます。今回は、describe()の使い方について学びます。
まず、簡単なデータを作っておきます。
data = pd.DataFrame([[1,4,5,6],[2,1,3,5],[2,4,5,10],[4,1,5,0],[11,7,3,6]],
columns=['a','b','c','d'])
このデータについて、describe()を適用してみたいと思います。
data.describe()上記のコードを実行すると、別のデータが出力されます。
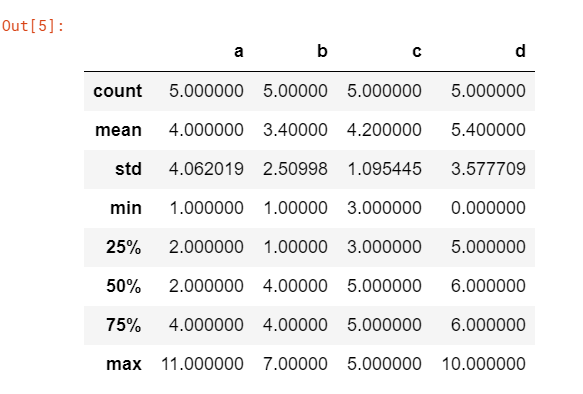
このデータには、いくつかのindexが含まれています。indexには、”mean”や”std”などと名前が付いています。
各要素が示す意味は以下の通りです。
| count | データの数 |
| mean | 平均値 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 第一四分位数 |
| 50% | 第二四分位数(中央値) |
| 70% | 第三四分位数 |
| max | 最大値 |
文字列を含むデータの場合、ユニークな値の数を示すuniqueや、最も出現回数が多い要素を示すtopといった情報を確認することができます。
平均値や標準偏差といった重要な統計量を瞬時に取得することができるので、とても便利です。
describe()の引数
describe()には、いくつか引数があります。
①percentiles (デフォルトではNone)
デフォルトでは第一四分位数(25%)、第二四分位数(50%)、第三四分位数(75%)を含むデータを返すよう設定されていますが、このパーセンテージを変更することができます。
例えば、第一四分位数を20%、第二四分位数を45%、第三四分位数を70%としたい場合は、percentiles=[0.2,0.45,0.7]と指定します。
②include (デフォルトではNone)
統計量を計算するデータ型を指定します。include=’all’とすると、全てのデータ型が指定されます。
③exclude (デフォルトではNone)
除外するデータ型を指定します。例えば、文字列と整数を含むデータについて、文字列が入っているカラムだけを除外したい時に使います。
④ datatime_is_numeric ( デフォルトではNone)
月日や時間を含むデータ(datatime)を数値として扱うかどうかを指定します。数値として扱う場合はTrue、そうでない場合はFalseとします。
まとめ
- describe()を使うと、データの平均値や標準偏差、最大値などを簡単に確認できる。
- 引数を活用することで、扱うデータに適した分析ができる。
