
Pandasには、相関係数を簡単に計算することができる便利なメソッドがあります。今回は、この使い方を説明します。
相関係数とは?
相関係数とは、2つのデータがどれくらい類似しているかを示す指標です。
例えば、天気とテーマパークの混雑度の関係を考えます。
この場合、天気が良い時ほど、多くの人がテーマパークに訪れると考えられるので、混雑度は高くなるでしょう。
天気の良さを表すデータの1つとして、降水確率が挙げられます。
降水確率が高いほど天気が悪く、低いほど天気が良くなる確率が高くなります。
つまり、降水確率が低ければテーマパークは混雑し、高ければガラガラになるでしょう。
したがって、降水確率と混雑度にはある程度の類似性があると考えられます。このような関係を、数値で表すことができるのが「相関係数」です。
なお、上記の降水確率と混雑度のように、類似性があるデータ同士は「相関関係」があると言えます。相関関係があるデータを調べることで、データを分析する上で重要なデータとそうでないデータを振り分けることができます。
手計算で相関係数を計算するのは時間がかかりますが、Pandasのcorr()メソッドを使えば、一瞬で値を求めることができます。
相関係数は-1から1まで
相関係数は、-1から1までの範囲に含まれます。
つまり、相関係数が1より大きくなることや、-1より小さくなることはありません。
相関係数がプラスの場合は、データ間に「正の相関」が、マイナスの場合は「負の相関」があります。なお、相関係数が0に近い場合はデータ間に相関がほぼないと考えることができます。
corr()の使い方
corr()はPandasに入っているメソッドなので、使用する場合はPandasをimportする必要があります。
corr()を使うと、特定のデータフレームに含まれているデータ同士の相関係数を計算できます。具体的には、次のように書きます。
データとして、今回は2020年12月1日から12月15日までの東京と札幌の最高気温のデータを使いたいと思います。(数値はgoo天気より)
import pandas as pd
tokyo=[14.9,10.2,10.6,13.9,7.7,13.5,16.1,17.2,12.2,12.2,14.4,15,15.4,13.1,11.3]
sapporo = [0.9,1.9,2,2.9,6.4,7.1,5.8,2.5,4.1,7.6,6.1,4.3,1.7,-1.5,-2.5]
df = pd.DataFrame({"Tokyo":tokyo,"Sapporo":sapporo})
print(df)まずは、データを作成します。pd.DataFrame()を使うと、簡単にデータフレームを作ることができます。今回は2つのリストを1つのデータフレームにするので、{“カラム名”:リスト}のようなdictionary形式でカラムを定義しています。
それでは、作成したデータをもとに相関係数を計算したいと思います。
print(df.corr())相関係数を計算するには、“データフレームの名前”.corr()とすれば良いです。これを実行すると、相関係数が含まれたデータフレームが出力されます。
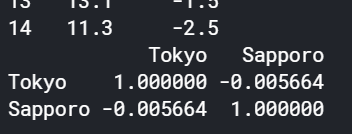
結果を見ると、東京の最高気温と札幌の最高気温の相関係数は、-0.005664であることが分かりました。この値から、東京と札幌の最高気温にはほとんど相関がないと考えることができます。
まとめ
- 相関係数→データ間の類似性を評価できる指標
- 相関係数は-1以上1以下、プラスの場合は正の相関があり、マイナスの場合は負の相関がある
- Pandasでは、corr()を使うと相関係数を一瞬で計算できる
